話者の少ない言語に対応した翻訳AIを開発し、オープンソース化する試み
パロアルトインサイトの嶋崎です。AIの活用分野の中でも「言語の翻訳」は私たちの生活に密接に関わっており、その利便性を身近に感じられます。
翻訳AIの進歩を感じている方も多いかと思いますが、実はその恩恵は英語などの主要な言語のみに集中しているのです。他の言語が放置されることに危機感を持ったMetaが進めてきたプロジェクト「No Language Left Behind (NLLB)」を紹介します。

シリコンバレーから現役データサイエンティストのインサイトをお届けする「The Insight」。今回取り上げるのは、Metaによる翻訳AIの開発プロジェクトです。
論文データ:今回のディスカッション対象の論文をご紹介します。
タイトル:No Language Left Behind: Scaling Human-Centered Machine Translation
著者:NLLB Team
掲載サイト:arXiv
発行日:2022年7月11日
引用数:
URL:https://arxiv.org/abs/2207.04672
まずNLLBがどんなプロジェクトなのかを解説します。
プロジェクト名の「No Language Left Behind」を日本語に訳すと、「どの言語も置き去りにしない」という意味です。
これまで自然言語処理AIの研究対象は英語やフランス語、ドイツ語などの主要な言語に集中してきました。この流れを放置すれば、AI翻訳の技術がどれだけ進歩したとしても、主要な言語の話者しかその恩恵を受けられません。研究対象とされてこなかった言語は、論文では「低リソース言語(low-resource language)」と呼ばれています。
NLLBの目的は、低リソース言語に対応できる翻訳AIを開発し、進歩に取り残される人々が生まれないようにすることです。あらゆる言語の使用者が、言語の壁を超えて、世界中の人々と交流できる未来を目指してます。
なお自然言語処理AIについては、過去記事「自然言語処理モデルGPT-3を越えた「InstructGPT」や「BERT(自然言語処理)の学習時間を削減する「モデル圧縮」とは」で詳しく解説しています。ぜひあわせてお読みください。
2022年7月、200もの言語の翻訳に対応できるAI「NLLB-200」が公開されました。このモデルを含むNLLBの成果はオープンソース化され、GitHubで公開されています。Meta以外の研究者であっても、NLLPの成果を自由に利用して、自らの翻訳ツールを開発することが可能です。
MetaはNLLBの成果をオープンソース化することで、他の研究者がより多くの言語に適用することを促そうとしているのです。この方針によって、NLLB-200はさらに多くの言語へと、適応範囲を拡大できる可能性があります。
今後NLLPの研究成果は、以下のような場所での翻訳で、実際に利用される予定です。
メタバースにリアルタイム翻訳の機能が加わわることで、国境を超えてあらゆる人々と簡単に交流できるようになります。対面よりも快適な会話がメタバース内で実現することになれば、社会的に大きなインパクトがあるでしょう。
NLLBの成果物は、以下の3つの要素で構成されています。また、それぞれの要素の代表例も挙げました。
AIではなく人が作成したデータセットを重視している点が、NLLBの特徴だといえます。これらの成果物の関連性を図示したのが下図です。
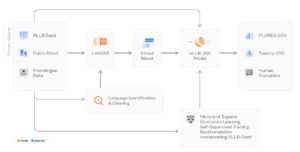
この図を整理すると、翻訳は大まかに言って以下の3ステップで行われます。それぞれのステップで、どの成果物が使われるのかも整理しました。
各ステップで技術的な課題があり、それらを乗り越えながらNLLBプロジェクトは進められてきました。課題とその対処法について、順に詳しく解説していきましょう。
AIの活用提案から、ビジネスモデルの構築、AI開発と導入まで一貫した支援を日本企業へ提供する、石角友愛氏(CEO)が2017年に創業したシリコンバレー発のAI企業。
社名 :パロアルトインサイトLLC
設立 :2017年
所在 :米国カリフォルニア州 (シリコンバレー)
メンバー数:17名(2021年9月現在)
パロアルトインサイトHP:www.paloaltoinsight.com
お問い合わせ、ご質問などはこちらまで:info@paloaltoinsight.com

2010年にハーバードビジネススクールでMBAを取得したのち、シリコンバレーのグーグル本社で多数のAI関連プロジェクトをシニアストラテジストとしてリード。その後HRテック・流通系AIベンチャーを経てパロアルトインサイトをシリコンバレーで起業。東急ホテルズ&リゾーツのDXアドバイザーとして中長期DX戦略への助言を行うなど、多くの日本企業に対して最新のDX戦略提案からAI開発まで一貫したAI・DX支援を提供する。2024年より一般社団法人人工知能学会理事及び東京都AI戦略会議 専門家委員メンバーに就任。
AI人材育成のためのコンテンツ開発なども手掛け、順天堂大学大学院医学研究科データサイエンス学科客員教授(AI企業戦略)及び東京大学工学部アドバイザリー・ボードをはじめとして、京都府アート&テクノロジー・ヴィレッジ事業クリエイターを務めるなど幅広く活動している。
毎日新聞、日経xTREND、ITmediaなど大手メディアでの連載を持ち、 DXの重要性を伝える毎週配信ポッドキャスト「Level 5」のMCや、NHKラジオ第1「マイあさ!」内「マイ!Biz」コーナーにレギュラー出演中。「報道ステーション」「NHKクローズアップ現代+」などTV出演も多数。
著書に『AI時代を生き抜くということ ChatGPTとリスキリング』(日経BP)『いまこそ知りたいDX戦略』『いまこそ知りたいAIビジネス』(ディスカヴァー・トゥエンティワン)、『経験ゼロから始めるAI時代の新キャリアデザイン』(KADOKAWA)、『才能の見つけ方 天才の育て方』(文藝春秋)など多数。
実践型教育AIプログラム「AIと私」:https://www.aitowatashi.com/
お問い合わせ、ご質問などはこちらまで:info@paloaltoinsight.com
 |
 |
※石角友愛の著書一覧
毎週水曜日、アメリカの最新AI情報が満載の
ニュースレターを無料でお届け!
その他講演情報やAI導入事例紹介、
ニュースレター登録者対象の
無料オンラインセミナーのご案内などを送ります。






 いまこそ知りたいDX戦略 自社のコアを再定義し、デジタル化する
いまこそ知りたいDX戦略 自社のコアを再定義し、デジタル化する  “経験ゼロ”から始める AI時代の新キャリアデザイン
“経験ゼロ”から始める AI時代の新キャリアデザイン  いまこそ知りたいAIビジネス
いまこそ知りたいAIビジネス